In this blog, I will be taking you on a journey of building the scalable and efficient IAC solution that we build for our multi-tenant system. Here we are not going to debate why we chose the CDK; that will be another discussion that can be highlighted in another blog. Instead, how we approached solving using AWS CDK is going to be discussed in this blog. Even if you are not very familiar with CDK, this blog can help to build a mental model of how we can think while writing the code for the infrastructure of such a complex system.
What are Multi-tenant Systems?
A multi-tenancy architecture uses a single instance of a software application to serve multiple customers. Each customer is referred to as a tenant. Tenants can customize certain aspects of the application, such as the color of the user interface or business rules, but they cannot change the application’s code.
There are three main types of multi-tenant architecture.
- One Application, One Database: All tenants share a single database.
- One Application, Multiple Databases: Each tenant has its own database that shares the same application instance.
- Multiple Applications and Databases: This is the most complex architecture, where multiple services and databases are deployed for each tenant.
In this blog, we will focus on the third architecture, which provides greater flexibility and isolation.
What is AWS CDK?
The AWS Cloud Development Kit (CDK) is an open-source software development framework that allows us to define and provision cloud infrastructure resources with a variety of programming languages.
AWS CDK, which is built on TypeScript, is tightly integrated with AWS CloudFormation, allowing it to leverage its strengths in infrastructure state management. In fact, CDK handles state management in the same way that CloudFormation does, making it easier to manage cloud resources.
Understanding Our Requirements
Our use case involves the linear growth of services alongside the exponential growth of tenants. A critical requirement is that each tenant must have database isolation to ensure robust tenant data integrity and confidentiality. This leads us to choose an architecture where services and databases for each tenant are deployed in isolation.
Key requirements include:
- Quick Tenant Onboarding: The onboarding process for new tenants should be streamlined.
- Service Types: We will differentiate between internal platform services (used internally) and product services (used by end-users), ensuring that platform services can communicate with product services across all tenants.
Architectural Overview
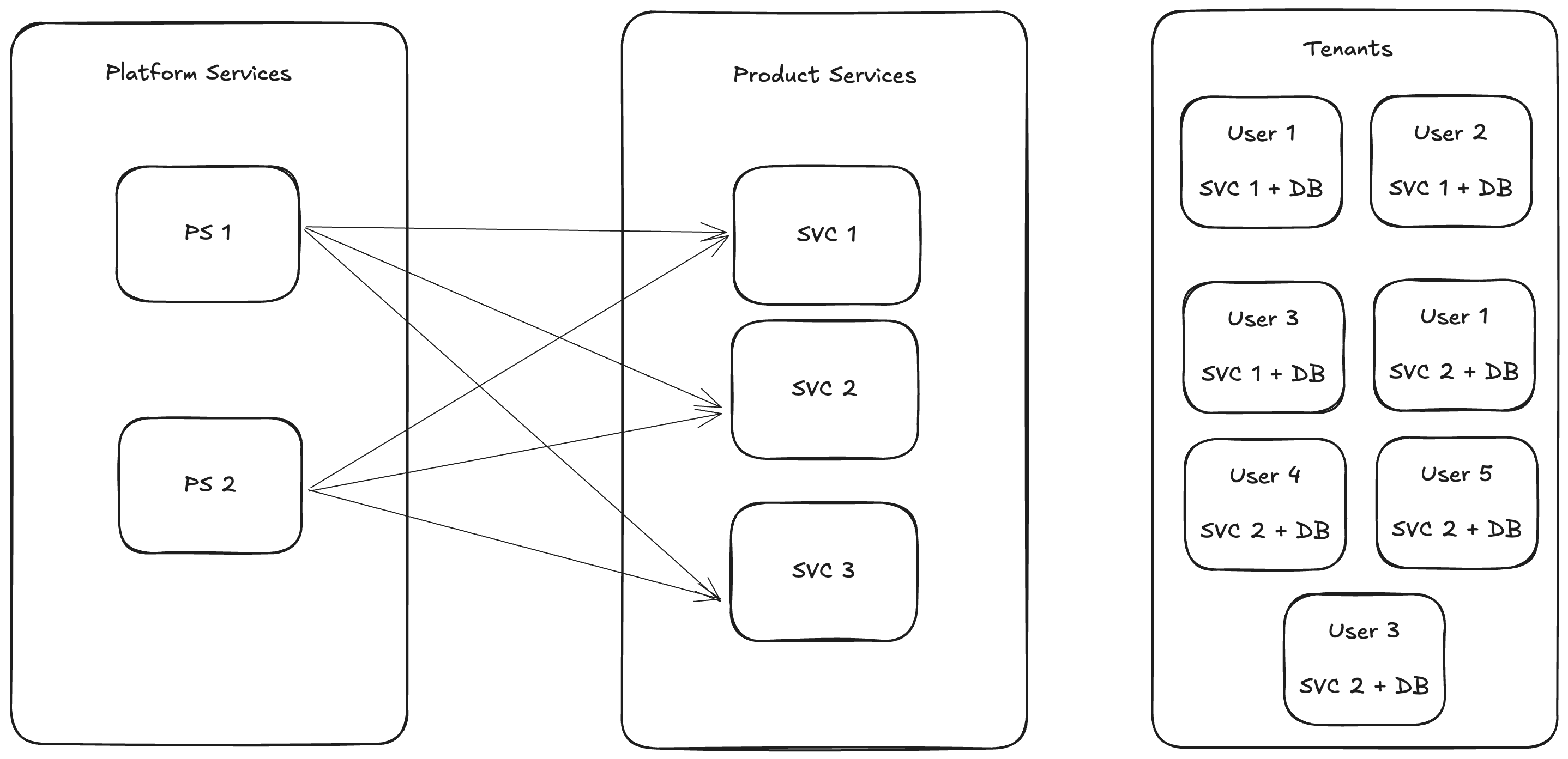
To visualize our architecture, consider the following components:
- Platform Services: These are internal services that interact with product services across all tenants. For example, if SVC 1 is deployed for three tenants, User1, User2, and User3, platform services will connect with these isolated instances.
- Product Services: These services address specific business needs and are deployed individually for each tenant, complete with their own databases.
- Tenants: The end-users who utilize these services, ensuring they only access their own data due to database isolation.
What do we know?
Now let’s briefly see what all things we have in our bucket and what is expected from IAC.
As we were using AWS as our cloud provider, we started looking into finalizing the architecture that we were going to use for our system. After all the R&D, we decided to go with the Multi-VPC architecture that is one of the recommendations from AWS, and yes, this was written in AWS CDK. And hence, taking recommendations from this CDK solution, we were able to achieve a single VPC for a single tenant, which then solved our complete isolation problem along with the platform VPC connectivity with the tenant VPCs. We will be looking at this in detail in this blog too.
Considering we have what we wanted for our networking infrastructure, then for applications we are going to use Fargate ECS services, RDS for databases, SSM for application environment variables, Secret Manager for application secrets, and Route 53 for maintaining the DNS records.
And for continuous integration and continuous deployment, we are going to use GitHub Actions. From all this decision, you might realize that we are avoiding anything self-hosted for now.
Before we start looking into CDK code, let me tell you I will only be going through the configuration file with you, not the actual code, because CDK only differs from other IAC tools in that it is written in imperative form, which means we make the configuration file public-facing and the actual code an abstraction, which then helps each member of the org to just learn how to manipulate the configuration file and not the actual code, which helps the infrastructure manipulation be very easy, quick, and scalable.
IAC of Networking
Let’s first start looking into how we break down the recommended networking architecture to fit our solution.
We took the reference from this config file. Let’s see how we can visualize this configuration file and how the actual output will look, which can be understood by the below diagram.
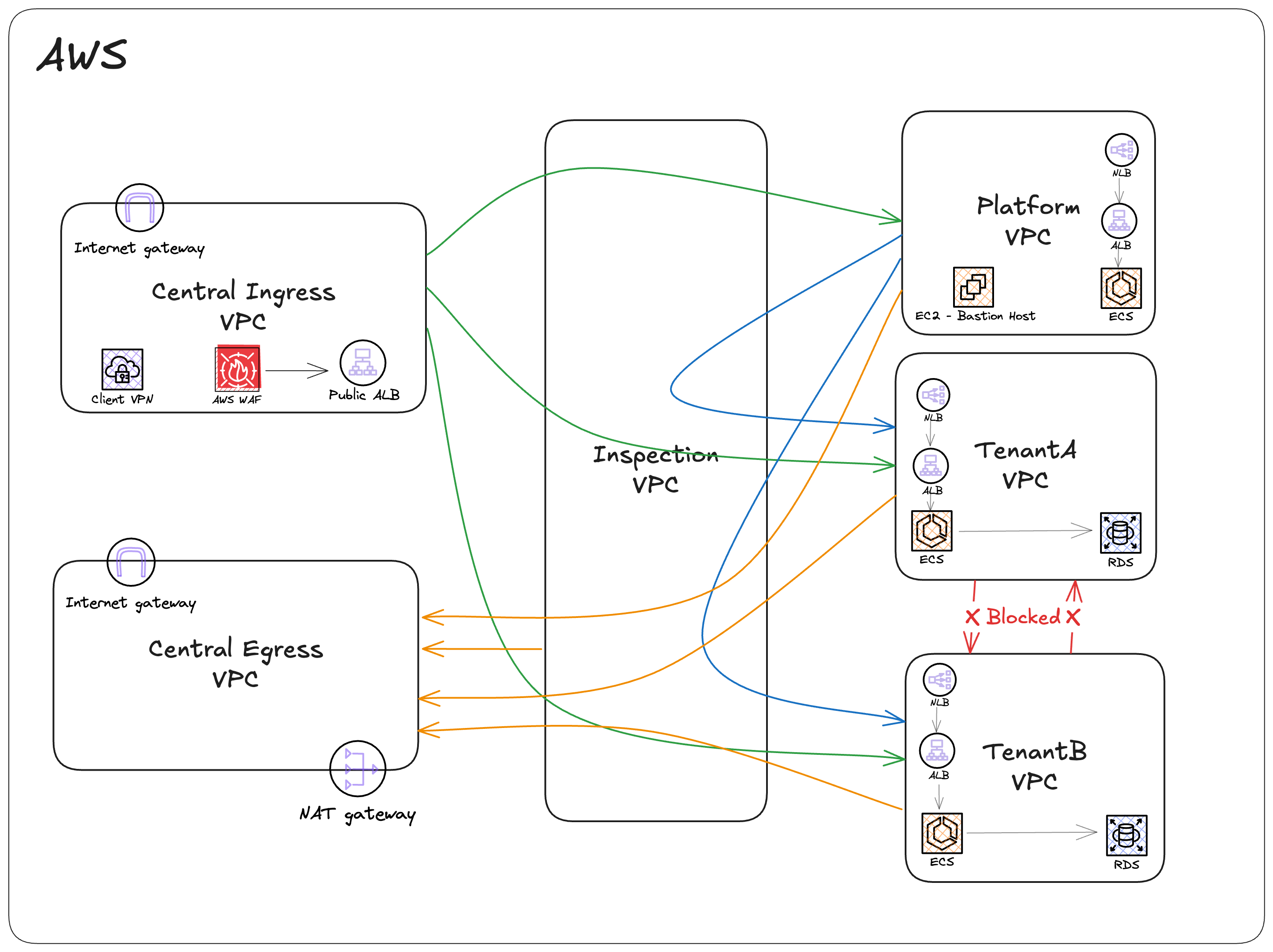
Let’s discuss in a bit what the components are. Although most of the components are self-explanatory, first start with
Transit Gateway: I haven’t mentioned it in the diagram, but to communicate between VPCs, we used the central transit gateway and added the required routes to the dynamicRoutes and defaultRoutes
transitGateways:
central:
style: transitGateway
tgwDescription: Central Transit Gateway
dynamicRoutes:
- vpcName: CentralIngress
routesTo: PlatformVpc
inspectedBy: inspectionVpc
- vpcName: CentralIngress
routesTo: TenantVpcA
inspectedBy: inspectionVpc
- vpcName: CentralIngress
routesTo: TenantVpcB
inspectedBy: inspectionVpc
- vpcName: PlatformVpc
routesTo: TenantVpcA
inspectedBy: inspectionVpc
- vpcName: PlatformVpc
routesTo: TenantVpcB
inspectedBy: inspectionVpc
defaultRoutes:
- vpcName: inspectionVpc
routesTo: centralEgress
- vpcName: PlatformVpc
routesTo: centralEgress
inspectedBy: inspectionVpc
- vpcName: TenantVpcA
routesTo: centralEgress
inspectedBy: inspectionVpc
- vpcName: TenantVpcB
routesTo: centralEgress
inspectedBy: inspectionVpc
Inspection VPC: This is our firewall VPC, which is going to be middleware between each communication between cross VPC.
providers:
firewall:
inspectionVpc:
vpcCidr: 100.64.0.0/16
useTransit: central
style: awsNetworkFirewall
firewallDescription: For Inspection Vpc
firewallName: InspectionEgress
For incoming traffic from the internet, Central ingress is considered the ingress VPC, and similarly, central egress is the VPC from where all traffic will go out to the internet.
providers:
internet:
centralEgress:
vpcCidr: 10.10.0.0/16
useTransit: central
style: natEgress
vpcs:
CentralIngress:
style: workloadPublic
vpcCidr: 10.1.0.0/19
subnets:
loadBalancerSubnet:
cidrMask: 22
PlatformVpc:
style: workloadIsolated
vpcCidr: 10.3.0.0/16
providerInternet: centralEgress
subnets:
workloadSubnet:
cidrMask: 24
databaseSubnet:
cidrMask: 24
loadBalancerSubnet:
cidrMask: 24
Platform VPC has connectivity with tenants VPCs, and tenants are not having cross-connectivity, as we can verify this with dynamicRoutes.
This setup was the first milestone as a part of the infrastructure, as now to onboard any new tenants we just need to add a small block of code and the routes, like below.
vpcs:
TenantVpcC:
style: workloadIsolated
vpcCidr: 10.9.0.0/16
providerInternet: centralEgress
subnets:
workloadSubnet:
cidrMask: 24
databaseSubnet:
cidrMask: 24
loadBalancerSubnet:
cidrMask: 24
transitGateways:
central:
style: transitGateway
tgwDescription: Central Transit Gateway
dynamicRoutes:
- vpcName: CentralIngress
routesTo: TenantVpcC
inspectedBy: inspectionVpc
- vpcName: PlatformVpc
routesTo: TenantVpcC
inspectedBy: inspectionVpc
defaultRoutes:
- vpcName: TenantVpcC
routesTo: centralEgress
inspectedBy: inspectionVpc
Moving forward from networking to application was going to be a little tricky because, considering this networking setup using CDK, we have to be sure that we maintain the consistency across networking and application code for infrastructure.
So we had two options: either edit the same code to add another support for the application or create a new CDK project that will only care about the application, considering the networking part is already set up.
We chose to go with the second approach because
- Changes in application-related configuration will be more aggressive than networking.
- To make application configuration manipulated by developers, we have to keep the unusual data, according to developers, as little as possible in the same place.
- Changes in networking configuration can impact the entire ecosystem, and hence maintenance of that should only come under specific teams like SRE/DevOps and should not be available to manipulate so easily by any member of the organization.
- By keeping application IAC separate, it also helps in automating the CI/CD, which is also another topic we can discuss in a further blog.
IAC of Application
The basic idea of writing AWS CDK code is to bundle the unit of deployment into the same stack. CDK Stack represents a single CloudFormation stack, which is a collection of resources that are deployed together. So here, I have created the stack with a collection of resources that are going to be deployed together and are linked.
This is the most important thing to identify upfront: how much power you want to give on manipulation from the configuration file, because if you try to write the CDK code very generically, then it will, at the end, be going to become like a CloudFormation template, and if you keep everything very coupled, then it will also be going to be a challenge if you want to decouple that.
For example, here I created one type of service stack by identifying the business need: ecsWithAlbNlbEfs, in which the ECS service, along with the log group, ALB, EFS, and NLB, is also going to be deployed.
services:
servicea:
type: ecsWithAlbNlbEfs
image: 123456789012.dkr.ecr.ap-south-1.amazonaws.com/servicea:v1.0.0
desiredCount: 2
memoryLimitMiB: 512
cpu: 1024
ephemeralStorageGiB: 10
From the angle, if you see this, it will help you quickly deploy a similar kind of service, but what if service requirements come like it doesn’t want EFS or NLB? Then what? Either you will update that stack and make the creation of NLB and EFS dynamic, or you can create another stack.
AWS CDK is imperative, and making it dynamic can break in the future if you want to update a single type of service, and the impact will be on all the services with entire tenants, so to avoid such an incident, I must suggest creating a different bundle of stack for different types of services use cases, and when a new type of service requirement comes, just create a new service stack instead of updating the existing one.
services:
servicea:
type: ecsWithAlbNlbEfs
image: 123456789012.dkr.ecr.ap-south-1.amazonaws.com/servicea:v1.0.0
desiredCount: 2
memoryLimitMiB: 512
cpu: 1024
ephemeralStorageGiB: 10
serviceb:
type: ecsWithAlbNlbWithoutEfs
image: 123456789012.dkr.ecr.ap-south-1.amazonaws.com/serviceb:v1.0.0
desiredCount: 2
memoryLimitMiB: 512
cpu: 1024
ephemeralStorageGiB: 10
So identifying the boundary of what to keep together and what to do differently with respect to the stack should be identified carefully; else there will be some efforts required to move resources from a stack to another.
This above is the architecture overview of application infrastructure written in AWS CDK. From configuration file to visualization, it will help us understand how to write the CDK stacks to make tenants and service onboarding easier.
We created a bunch of stacks by identifying the problems.
Common Infrastructure Stack
This is the first stack that we have written to create common IAM roles that are going to be used globally, such as the ECS task execution role and the GitHub Actions role.
ECS Service Stack (with EFS)
The stack creates the ECS service for the tenant cluster by identifying via the configuration file alongside the ALB, NLB, EFS, and security groups.
RDS Stack
Keeping the stateful resources separate is one of the best practices that we followed, and hence the creation of the RDS stack is kept in a different stack along with the KMS key, security groups, and updating the secret manager with RDS credentials.
Public ALB
This is one of the common stacks we identified to create a public-facing application load balancer separately by following the practices of attaching ACM and proper security groups.
Internal ALB
CDK Stack that is used to create a separate internal ALB, such as in the platform VPC, to communicate with the tenants VPC services
Conclusion
In conclusion, building a scalable and efficient multi-tenant system on AWS requires careful planning and design. By using AWS CDK, we were able to define and provision our cloud infrastructure resources in a flexible and scalable way. Our approach to separating IAC code for networking and applications allowed us to maintain consistency and make changes more easily. We hope that this blog post has provided a useful example of how to use AWS CDK to build a multi-tenant system.
We look forward to sharing more of our experiences in future blog posts, with follow-up questions like below.
- How to automate CDK infrastructure provisioning with GitHub Actions?
- When to choose CDK over Terraform?
- What are the downsides of choosing a multi-VPC AWS architecture?
- How do you design a scalable deployment pipeline for multiple services and tenants?
- How do you plan for disaster recovery?
- How to optimize multi-VPC architecture to reduce costs?


